Hyper-V のゲスト OS が一斉に一時停止になってさあ大変 Hyper-V のゲスト OS から共有しているフォルダにアクセスしようとすると、ネットワークリソースにアクセスできないという旨のメッセージが出ました。

そこで、Hyper-V マネージャーを見てみると、すべてのゲスト OS が一時停止状態となっていたため、イベントビューアを調べてみると、以下のエラーが記録されていました。
このエラーは、イベントビューアより、「アプリケーションとサービスログ」→「Microsoft」→「Windows」→「Hyper-V-VMMS」から参照することができます(イベントID 16060)。
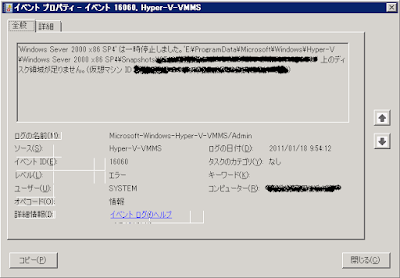
どうやら、ゲスト OS 用に割り当てた仮想ハードディスク (.vhd) が膨れ上がってしまい、ハードディスクの空き容量が少なくなってしまったたために、登録されているすべてのゲスト OS が Hyper-V の 仮想マシン管理サービスプロセス(VMMS)によって一時停止状態となったようです。
仮想ハードディスクが膨れ上がった原因を調べてみると、次のことがわかりました。
- 仮想ハードディスクの形式が可変になっていた。
- スナップショットが複数存在していた
上記のために、いつの間にか膨れ上がった仮想ハードディスクが実際のハードディスク領域を圧迫していた模様です。
こうなったら仮想ハードディスクを固定にするしかない 限りあるコンピュータ資源であるハードディスクの空きがあまりないということで、今回のような現象が発生すると、これ以上仮想ハードディスクが膨らまないように対応するしかありません。
仮想ハードディスクの形式を可変から固定に変換すれば、ディスク容量はそれ以上は大きくなりません。
仮想ハードディスクの形式を可変から固定に変換する作業自体はそれほど難しくはないのですが、スナップショットが存在する場合は、先にスナップショットを親仮想ディスクに結合しなければなりません。
以下のような仮想ハードディスク構成になっているとします。
Windows Server 2000 x86.vhd <--- 親仮想ディスク
Windows Server 2000 x86[ユニークID].avhd <--- 差分仮想ディスク1
Windows Server 2000 x86[ユニークID].avhd <--- 差分仮想ディスク2
Windows Server 2000 x86[ユニークID].avhd <--- 差分仮想ディスク3(最新)
上記で.avhd がスナップショットで作成される差分仮想ハードディスクとなります。
このように、
一つでも差分仮想ハードディスクが存在する場合は、ディスク形式を変換する前に親ディスクにディスクを結合しなければならなくなりますので、注意が必要です。
上記の例では 3 の差分仮想ハードディスクが最新となっていますので、3、2、1 の順に計 3 回の結合作業が必要となります(3 回結合が完了すると、Windows Server 2000 x86.vhd だけになる)。
差分仮想ハードディスクの結合方法 差分仮想ハードディスクを親仮想ディスクに結合するには、ゲスト OS をシャットダウンしてから、ディスクを解除します。
1. Hyper-V マネージャより、当該のゲスト OS を選択して設定画面を開き、下図のように IDE コントローラーから仮想ディスクを削除し、“適用”ボタンをクリックします。

「削除」という表現が紛らわしいですが、Hyper-V の管理下から解除されるという意味ですので、仮想ハードディスク自体はそのまま残ります。
2. 下図のように、Hyper-V のマシン名をマウスで右クリックするとサブメニューが開きますので、その中から「ディスクの編集(E)...」というメニュー項目を選択します。

仮想ハードディスクの編集ウィザードが開きますので、以下のように最新の差分仮想ディスク(.avhd)を指定します。

3. 仮想ハードディスクに対するアクションを選択するための画面に移りますので、下図のように「結合(M)」を選択し、“次へ”をクリックします。

4. 差分ディスク変更の結合をするための画面に映りますので、下図のように「親仮想ハードディスクに結合する(P)」を選択し、“次へ”をクリックします。

5. 以下のような確認画面が表示されますので、この内容でよければ“完了(F)”をクリックします。
差分仮想ハードディスクが親仮想ハードディスクに結合されます。
 注意)この手順を繰り返し、すべての差分仮想ハードディスクを親仮想ハードディスクに結合する必要がありますので、ディスク領域に余裕のあるハードディスク上でこの操作を行ってください。仮想ハードディスクを最適化する
注意)この手順を繰り返し、すべての差分仮想ハードディスクを親仮想ハードディスクに結合する必要がありますので、ディスク領域に余裕のあるハードディスク上でこの操作を行ってください。仮想ハードディスクを最適化する 上記で差分仮想ハードディスクがすべて結合されると、ディスクの中は下図のように仮想ハードディスクのみになります。

仮想ハードディスクのサイズ形式を可変から固定に変換する前に、以下の手順で仮想ハードディスクを最適化することによって、不使用の領域を取り除いておくことをお勧めします。
1. 下図のように、Hyper-V のマシン名をマウスで右クリックするとサブメニューが開きますので、その中から「ディスクの編集(E)...」というメニュー項目を選択します。
2. 仮想ハードディスクの編集ウィザードが開きますので、先ほど結合した仮想ハードディスクを指定し、“次へ”をクリックします。

3. 仮想ハードディスクに対する操作のメニュー項目が表示されますので、その中から一番上の「最適化(C)」を選択し、“次へ”をクリックします。

4. 確認画面が表示されますので、操作内容が最適化になっていることと、指定した仮想ハードディスクが正しいことを確認してから、“完了”をクリックすると、仮想ハードディスクが最適化されます。
 仮想ハードディスクのサイズ形式を可変から固定に変換する
仮想ハードディスクのサイズ形式を可変から固定に変換する 仮想ハードディスクを最適化した後は、サイズ形式を可変から固定に変換します。
1. 下図のように、Hyper-V のマシン名をマウスで右クリックするとサブメニューが開きますので、その中から「ディスクの編集(E)...」というメニュー項目を選択します。
2. 仮想ハードディスクの編集ウィザードが開きますので、先ほど結合した仮想ハードディスクを指定し、“次へ”をクリックします。
3. 仮想ハードディスクに対する操作のメニュー項目が表示されますので、その中から真ん中の「変換(V)」を選択し、“次へ”をクリックします。

4. 変換対象の仮想ハードディスクを選択するための画面に移りますので、先ほど最適化した仮想ハードディスクを選択してから、“次へ”をクリックします。

5. 確認画面が表示されますので、操作内容が「容量固定に変換」になっていることと、指定した仮想ハードディスクが正しいことを確認してから、“完了”をクリックすると、仮想ハードディスクのサイズ形式が固定に変換されます。
 変換済みの仮想ハードディスクを Hyper-V のIDE コントローラに繋ぎ直す
変換済みの仮想ハードディスクを Hyper-V のIDE コントローラに繋ぎ直す これで仮想ハードディスクのサイズ形式が固定になりましたので、Hyper-V の IDE コントローラに繋ぎ直して起動できれば操作は完了です。
1. Hyper-V マネージャより、当該のゲスト OS を選択して設定画面を開き、下図のように IDE コントローラーを左ペインで選択し、右ペインで「ハードドライブ」を選択してから“追加(D)”ボタンをクリックします。

2. 仮想ハードディスクファイルを選択する画面に移りますので、“参照(B)...”をクリックして先ほどサイズ形式を固定に変換した仮想ハードディスクを選択してから、“適用(A)”をクリックします。

3. IDE コントローラに仮想ハードディスクが適用されると、“適用(A)”ボタンが灰色反転しますので、“OK”をクリックします。

4. 今回適用したハードディスクを使ったゲスト OS を起動し、問題なく操作できれば完了です。
今回の障害で得られた教訓は次のとおりです。
1) 最初に仮想ハードディスクを割り当てる際は、予想されるディスク容量の形式を
固定にする。
2) スナップショットはある時点のシステム状態を再現するには便利な機能だが、仮想ハードディスク絡みのトラブルが発生して最適化や変換が必要になった場合に、すべてのスナップショットを一旦親ディスクに結合しなければならなくなるので、スナップショットを多用するのは得策とは言えない。

















































